








;)
;)





 이미지 확대보기
이미지 확대보기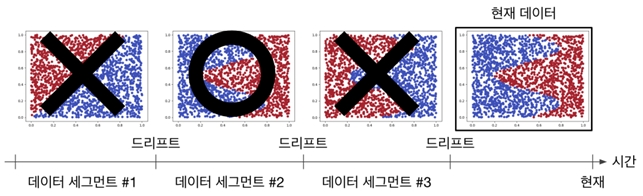
KAIST(총장 이광형)는 전기및전자공학부 황의종 교수 연구팀이 시간에 따라 데이터의 분포가 변화하는 드리프트 환경에서도 인공지능이 정확한 판단을 내리도록 돕는 새로운 학습 데이터 선택 기술을 개발했다고 14일 밝혔다.
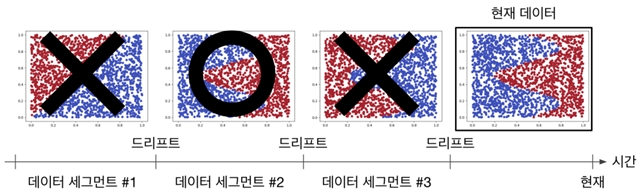
최근 인공지능이 다양한 분야에서 인간의 능력을 뛰어넘을 정도의 높은 성능을 보여주고 있지만, 대부분의 좋은 결과는 AI 모델을 훈련시키고 성능을 테스트할 때 데이터의 분포가 변하지 않는 정적인 환경을 가정함으로써 얻어진다. 하지만 이러한 가정과는 다르게 SK하이닉스의 반도체 공정 과정에서 시간에 따른 장비의 노화와 주기적인 점검으로 인해 센서 데이터의 관측값이 지속적으로 변화하는 드리프트 현상이 관측되고 있다.
시간이 지나면서 데이터와 정답 레이블 간의 결정 경계 패턴이 변경되면, 과거에 학습되었던 AI 모델이 내린 판단이 현재 시점에서는 부정확하게 되면서 모델의 성능이 점차 악화될 수 있다.
본 연구팀은 이러한 문제를 해결하기 위해 데이터를 학습했을 때 AI 모델의 업데이트 정도와 방향을 나타내는 그래디언트(gradient)를 활용한 개념을 도입해 제시한 개념이 드리프트 상황에서 학습에 효과적인 데이터를 선택하는 데 도움을 줄 수 있음을 이론적으로 실험적으로 분석했다. 그리고 이러한 분석을 바탕으로 효과적인 학습 데이터 선택 기법을 제안하여, 데이터의 분포와 결정 경계가 변화해도 모델을 강건하게 학습할 수 있는 지속가능한 데이터 중심의 AI 학습 프레임워크를 제안했다.
 이미지 확대보기
이미지 확대보기
본 학습 프레임워크의 주요 이점은, 기존의 변화하는 데이터에 맞춰서 모델을 적응시키는 모델 중심의 AI 기법과 달리, 드리프트의 주요 원인이라고 볼 수 있는 데이터 자체를 직접 전처리를 통해 현재 학습에 최적화된 데이터로 바꿔줌으로써 기존의 AI 모델 종류와 상관없이 쉽게 확장될 수 있다는 점에 있다. 실제로 본 기법을 통해 시간에 따라 데이터의 분포가 변화되었을 때에도 AI 모델의 성능, 즉 정확도를 안정적으로 유지할 수 있었다.
제1저자인 김민수 박사과정 학생은 "이번 연구를 통해 인공지능을 한 번 잘 학습하는 것도 중요하지만, 그것을 변화하는 환경에 따라 계속해서 관리하고 성능을 유지하는 것도 중요하다는 사실을 알릴 수 있으면 좋겠다"고 밝혔다.
연구팀을 지도한 황의종 교수는 "인공지능이 변화하는 데이터에 대해서도 성능이 저하되지 않고 유지하는 데에 도움이 되기를 기대한다"고 말했다.
본 연구에는 KAIST 전기및전자공학부의 김민수 박사과정이 제1저자, 황성현 박사과정이 제2저자 그리고 황의종 교수(KAIST)가 교신 저자로 참여했다. 이번 연구는 지난 2월 캐나다 밴쿠버에서 열린 인공지능 최고 권위 국제학술대회인 '국제 인공지능 학회(Association for the Advancement of Artificial Intelligence, AAAI)'에서 발표되었다(논문명: Quilt: Robust Data Segment Selection against Concept Drifts).
한편, 이 기술은 SK하이닉스 인공지능협력센터(AICC: AI Collaboration Center)의 지원을 받은 '노이즈 및 변동성이 있는 FDC 데이터에 대한 강건한 학습' 과제(K20.05)와 정보통신기획평가원의 지원을 받은 '강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습' 과제(2022-0-00157), 한국연구재단의 지원을 받은 '데이터 중심의 신뢰 가능한 인공지능' 과제 성과다.
이상훈 글로벌이코노믹 기자 sanghoon@g-enews.com






















