








;)
;)





딥시크 텍스트, 74.2%가 오픈AI와 일치
AI 학습에 오픈AI 의존, IP 논란 촉발
반도체 분야도 투자 대비 성과 '미미'
中, 2030년까지 AI에 2000억원 투자
AI 학습에 오픈AI 의존, IP 논란 촉발
반도체 분야도 투자 대비 성과 '미미'
中, 2030년까지 AI에 2000억원 투자
 이미지 확대보기
이미지 확대보기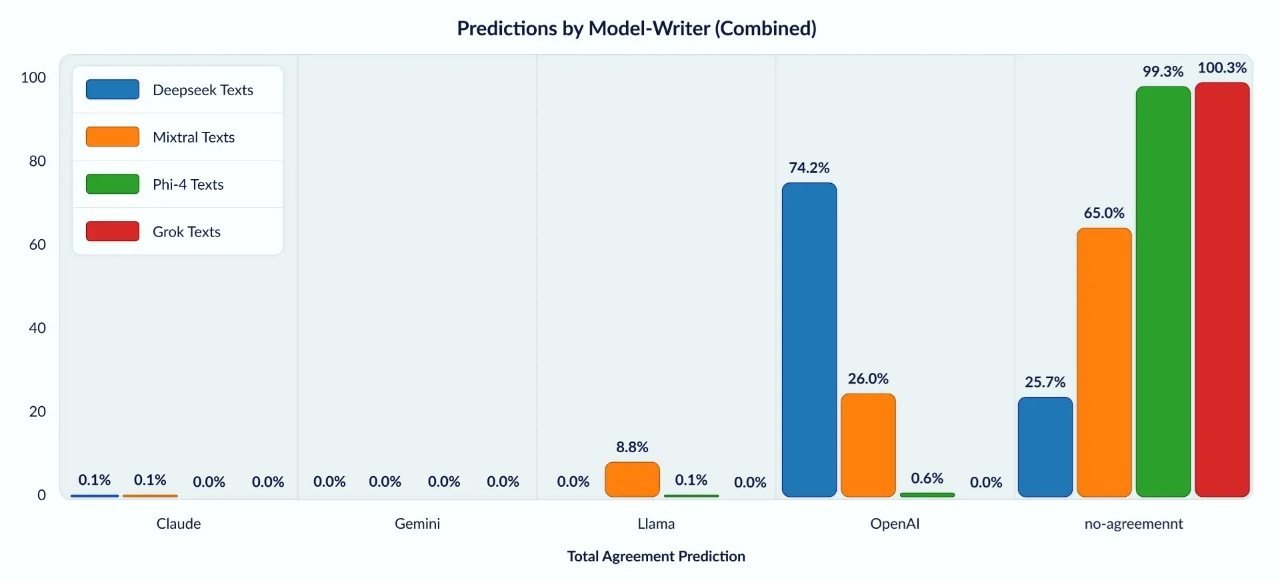
몇 달 전, 중국은 오픈AI보다 저렴한 가격으로 유사한 수준의 성능을 내는 생성형 AI '딥시크(DeepSeek)'를 선보였다. 딥시크는 중국의 AI 업체로 아직 설립 2년이 채 되지 않은 신생 기업이다. 그런데 딥시크의 'DeepSeek-V3'를 기반으로 하는 두 가지 메인 모델(R1, R1-Zero)이 공개되자 그 놀라운 수준에 세계가 충격을 먹었다. 또한 해당 AI를 학습시키는 데 약 80억원밖에 안 들었다는 점 그리고 학습 기간이 약 2개월에 불과하다는 것도 AI 업계를 뜨겁게 달궜다.
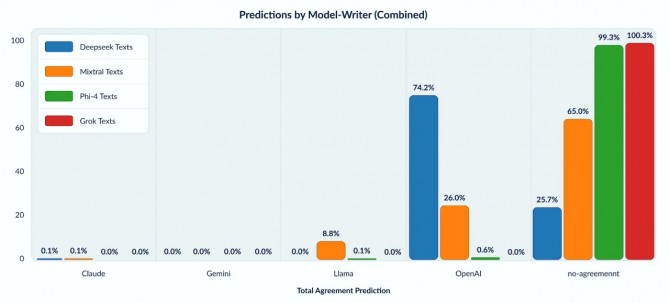
하지만 AI 거버넌스 및 표절 감지 전문 카피리크스(Copyleaks)가 3월 공개한 자료에 따르면 딥시크-R1에서 생성된 텍스트의 4분의 3(74.2%)이 오픈AI의 문체 지문과 일치하는 것으로 조사됐다.
카피리크스는 해당 연구에 만전을 기했다. 카피리크스는 클로드(Claude), 제미나이(Gemini), 라마(Llama), 오픈AI(OpenAI)로부터 텍스트를 수집해 각각 훈련된 3개의 고도화된 AI 분류기를 결합하는 방식으로 엄격하게 테스트했다. 이 분류기들은 문장 구조, 어휘, 표현 등 미묘한 문체적 특징을 식별했다. 특히 모든 분류기가 일치해야만 판정하는 ‘만장일치 배심원’ 시스템을 도입했다.
그 결과 99.88%의 높은 정밀도와 0.04%의 낮은 위양성(false positive)을 기록했다.
카피리크스는 "생성된 텍스트의 74.2%가 오픈AI의 스타일 지문과 일치해 독창성과 AI가 생성한 콘텐츠의 미래에 대한 중요한 의문을 제기했다"면서 "이와 대조적으로 마이크로소프트의 파이(Phi)-4 모델은 99.3%의 불일치율을 보였으며, 알려진 어떤 모델과도 유사성이 없고 독립적인 학습이 확인됐다"고 전했다.
앞서 중국 매체는 딥시크를 개발한 량원펑을 '중국의 올트먼'이라며 연일 띄웠다. 그가 평범한 초등학교 교사 밑에서 자랐다는 것, AI 기술이 아닌 금융 분야에서 경력을 쌓은 헤지펀드 매니저 기업가라는 점을 부각하며 중국의 자랑으로 만들었다.
하지만 '중국의 올트먼'이 만든 딥시크는 학습 과정에서 오픈AI에 전적으로 의존한 듯한 결과가 나왔다. 이는 지식재산권(IP)과 투명성, 윤리적인 AI 학습 등 전반에 걸쳐 딥시크의 숙제로 남게 될 전망이다.
중국의 이 같은 '용두사미(龍頭蛇尾)'는 이번이 처음은 아니다. 과거 중국 우한홍신반도체(HSMC)는 중국의 반도체 굴기 속 22조원에 달하는 막대한 지원금을 받으며 기대를 모았으나 2022년 갑작스레 모든 프로젝트를 중단하며 '먹튀'했다. 당시 현지 매체 보도에 따르면 반도체 공장의 인부들 월급이 8개월씩 밀렸다.
또 중국이 삼성전자와 TSMC를 따라잡겠다며 야심 차게 투자한 취안신집적회로(QXIC)도 정부와 지방정부의 막대한 지원을 받았으나 칩 생산 없이 결국 문을 닫았다. 이외에 화웨이, 하이테라 등도 미국 기업의 기술을 표절한 것이 알려지면서 국제적 망신을 샀다.
다만 중국을 무시해서는 안 된다는 목소리도 많다. 여러 잡음과 먹튀 논란이 일고 있지만 중국이 첨단 과학에 투자하는 비용은 실로 막대하기 때문이다. 특히 AI 분야에서 중국은 미국의 스타게이트에 맞서기 위해 2030년까지 6년간 약 2000조원을 투자할 계획이다.
이상훈 글로벌이코노믹 기자 sanghoon@g-enews.com






















