














 이미지 확대보기
이미지 확대보기
과학기술정보통신부와 정보통신기획평가원(IITP)의 혁신성장동력 프로젝트로 추진 중인 엑소브레인 사업 성과인 최첨단 한국어 언어모델을 공개했다. 이로써 인공지능(AI) 비서, AI 질의응답, 지능형 검색 등에 보다 풍부한 한국어 모델을 활용할 수 있게 됐다. 이를 활용하면 향후 보다 정교한 고도의 한국어 인공지능(AI) 서비스 개발이 이뤄질 수 있다는 것을 의미한다.
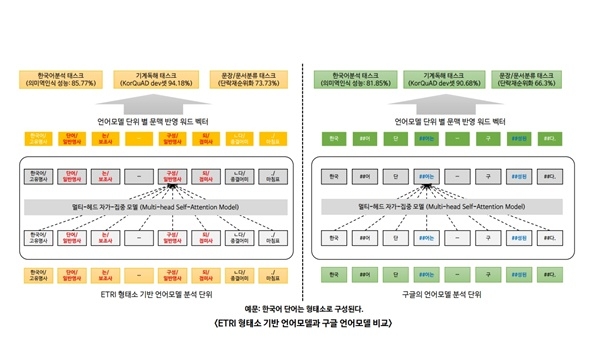
ETRI 연구진이 개발한 모델은 구글의 언어표현 방법을 기반으로 더 많은 한국어 데이터를 넣어 만든 언어모델과 한국어의 ‘교착어’ 특성까지 반영해 만들어졌다. 이 기술은 올해 3월 한컴오피스 지식검색 베타버전에도 탑재됐다. ETRI는 하반기 중 이 언어모델을 활용한 ‘법령분야 질의응답 API’를 추가 공개하고 ‘유사 특허 지능형 분석 기술’ 출시를 목표하고 있다.
연구진은 이번 한국어에 최적화된 언어모델이 ▲전처리 과정에서 형태소를 분석한 언어모델 ▲한국어에 최적화된 학습 파라미터 ▲방대한 데이터 기반 등이 구글과 차별성 있는 특징이라고 설명했다.
 이미지 확대보기
이미지 확대보기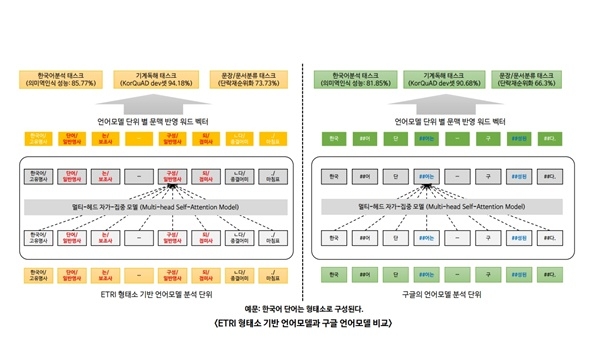
개발된 언어모델은 성능을 확인하는 5가지 기준에서 구글이 배포한 한국어 모델보다 성능이 평균 4.5% 가량 우수했다. 특히 단락 순위화(Passage Ranking) 기준에서는 7.4%나 높은 수치를 기록했다.
현재 구글과 연구진이 언어모델 개발에 활용한 BERT 방식은 약 512개 이상의 단어가 들어간 문서를 한 번에 처리하지 못한다. 향후 연구진은 한 번에 더욱 많은 언어 데이터를 처리하고 검증 방법을 고도화한 모델을 개발할 계획이다.
개발된 언어모델은 대표적인 딥러닝 프레임워크인 파이토치(PyTorch)와 텐서플로우(Tensorflow) 환경 모두에서 사용할 수 있으며 공공 인공지능(AI) 오픈 API‧데이터 서비스 포털에서 쉽게 찾아볼 수 있다.
엑소브레인 사업의 총괄책임자인 김현기 ETRI 박사는 “한국어에 최적화된 언어모델을 통해 한국어 분석, 지식추론, 질의응답 등의 다양한 한국어 딥러닝 기술의 고도화가 가능할 것으로 기대된다”고 말했다.
김지원 과학기술정보통신부 인공지능정책팀 팀장도“AI 허브를 통해 정부 R&D를 통해 개발되는 양질의 인공지능 SW API 및 데이터를 공개함으로써 개방형 혁신을 촉진할 수 있도록 노력하겠다”고 밝혔다.
언어처리를 위한 딥러닝 기술을 개발하기 위해서는 텍스트에 기술된 어절을 숫자로 표현해야 한다. 이를 위해 그동안 언어를 활용한 서비스를 개발하는 기관에서는 주로 구글의 다국어 언어모델 ‘버트’(BERT)를 사용했다. 버트는 문장 내 어절을 한 글자씩 나눈 뒤, 앞뒤로 자주 만나는 글자끼리 단어로 인식한다. 이 방식은 지난해 11월 처음 공개되었을 때 언어처리 11개 분야에서 많은 성능 향상을 보이면서 주목을 받았다.
구글은 40여 만 건의 위키백과 문서 데이터를 사용해 한국어 언어모델을 개발했지만 ETRI 연구진은 여기에 23기가바이트(GB)에 달하는 지난 10년간의 신문기사와 백과사전 정보를 더해 45억개의 형태소를 학습시킴으로써 구글보다 많은 한국어 데이터를 기반으로 언어모델을 개발했다.
ETRI는 단순히 입력한 데이터 양만을 늘린 것이 아니라고 밝혔다. 연구진은 한글이 다른 언어와 달리 어근에 조사가 붙는 교착어여서 언어모델 고도화에 한계가 있다는 점을 감안한 연구를 진행했다. 즉 한국어의 의미 최소 단위인 형태소까지 고려해 한국어 특성을 최대한 반영한 언어모델을 만드는데 심혈을 기울였다.
 이미지 확대보기
이미지 확대보기
이번 연구개발에 근간이 된 ‘엑소브레인 사업’은 2016년 EBS 장학퀴즈 우승, 기술이전 및 사업화 39건, 국내외 표준화 44건, 특허출원 70건 등의 성과를 낸 바 있다.
특히 ETRI는 지난 2017년도 이래 언어지능 기술 오픈 API 및 기계학습 데이터를 공개했다. 지금까지 1300만 건 이상 활용됐고 산업체(42%), 대학교(34%), 개인(20%), 기타(4%)의 개발자들이 사용하고 있다. 또한 은행권·지자체를 대상으로 AI 대국민 서비스 등을 개발하며 국내 AI 분야의 산업화 촉진을 추진하고 있다고 밝혔다.
이재구 글로벌이코노믹 기자 jklee@g-enews.com





![[초점] Z세대 직장인들 스트레스 받게 하는 ‘직장 용어’ 으뜸은 ‘KPI’](https://nimage.g-enews.com/phpwas/restmb_setimgmake.php?w=184&h=118&m=1&simg=20241124192735025789a1f3094311109215171.jpg)











![[뉴욕 e종목] 리게티 컴퓨팅, 양자 컴퓨팅 시장 '다크호스' 될까...](https://nimage.g-enews.com/phpwas/restmb_setimgmake.php?w=80&h=60&m=1&simg=2024112507264205052e250e8e1885822911040.jpg)

![[2025 대한민국 대전망(5)] 2025년, 'AI 수퍼사이클'의 시작점.....](https://nimage.g-enews.com/phpwas/restmb_setimgmake.php?w=80&h=60&m=1&simg=2024112507063105449c35228d2f5175193150103.jpg)























